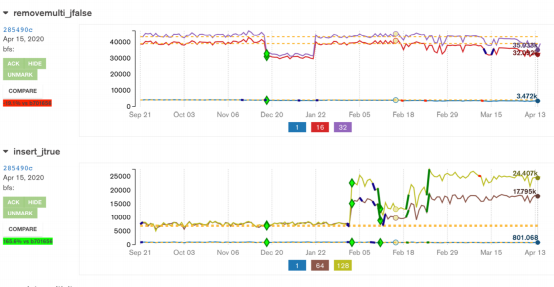
Performance Testing at MongoDB
MongoDB has the most advanced continuous performance testing I know about. It quite could be that some other companies have something interesting too – but they are not sharing that. [Another interesting project in that area is keptn, but that is about it. If I missed something interesting, please let …
