Performance Testing at MongoDB
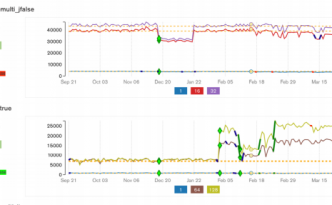
MongoDB has the most advanced continuous performance testing I know about. It quite could be that some other companies have something interesting …
MongoDB has the most advanced continuous performance testing I know about. It quite could be that some other companies have something interesting …

As I started to work for MongoDB, I started to get questions about MongoDB performance. We do have a lot of great …
Some time ago Federico Toledo published Performance Testing with Open Source Tools- Busting The Myths. While Federico definitely has good points there, …
The CMG Impact conference (February 10-12, 2020 in Las Vegas) is coming. Looking at the program I have the same problem as …
Following up my post Are Times still Good for Load Testing? , I decided to answer multiple comments here separately. First, I’d …
My post Good Times for Load Testing was published in 2014. It is difficult to believe that 5 years passed… Are times …
I was honored to write a preface to the great new book Master Apache JMeter. From load testing to DevOps. Here it …
Guest Post by Wendy Dessler Source-Pixabay When trying to develop a new piece of software or an app, one of the first things …
One software vendor ask me, along with a few other performance professionals, to answer questions related to performance trends. But they changed …
I am very excited by the upcoming CMG imPACt performance and capacity conference. This year it would be held on November 6-9, …