Performance Testing at MongoDB
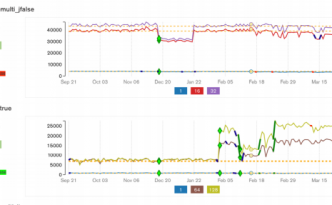
MongoDB has the most advanced continuous performance testing I know about. It quite could be that some other companies have something interesting …
MongoDB has the most advanced continuous performance testing I know about. It quite could be that some other companies have something interesting …

As I started to work for MongoDB, I started to get questions about MongoDB performance. We do have a lot of great …
The CMG Impact conference (February 10-12, 2020 in Las Vegas) is coming. Looking at the program I have the same problem as …
My post Good Times for Load Testing was published in 2014. It is difficult to believe that 5 years passed… Are times …
I am very excited by the upcoming CMG imPACt performance and capacity conference. This year it would be held on November 6-9, …
Well, let’s say CMG ImPACt would be the best on my memory at least in the area I am interested in: performance …
Tammy Everts (@tameverts) recently presented Web Performance ROI: A Brief History It is a very important topic in performance engineering and it …
The coming 2015 Performance and Capacity Conference by CMG looks great – the best ever in my opinion. While a very good …
The Performance and Capacity 2013 Conference by CMG will be held November 4th through 8th in La Jolla, CA. The program is …
My post Breaking Performance Silos was published by Speed Awareness Month.