Performance Engineering and Load Testing: A Changing Dynamic
There are many discussions about performance, but they often concentrate on only one specific facet of performance. The main problem with that is that performance is the result of every design and implementation detail, so you can’t ensure performance approaching it from a single angle only.
There are different approaches and techniques to alleviate performance risks, such as:
- Single-User Performance Engineering. Everything that helps to ensure that single-user response times, the critical performance path, match our expectations. Including profiling, tracking and optimization of single-user performance, and Web Performance Optimization (WPO).
- Software Performance Engineering (SPE). Everything that helps in selecting appropriate architecture and design and proving that it will scale according to our needs. Including performance patterns and anti-patterns, scalable architectures, and modeling.
- Instrumentation / Application Performance Management (APM)/ Monitoring. Everything that provides insights in what is going on inside the working system and tracks down performance issues and trends.
- Capacity Planning / Management. Everything that ensures that we will have enough resources for the system. Including both people-driven approaches and automatic self-management such as auto-scaling.
- Load Testing. Everything used for testing the system under any multi-user load (including all other variations of multi-user testing, such as performance, concurrency, stress, endurance, longevity, scalability, reliability, and similar).
- Continuous Integration / Delivery / Deployment. Everything allowing quick deployment and removal of changes, decreasing the impact of performance issues.
And, of course, all the above do not exist not in a vacuum, but on top of high-priority functional requirements and resource constraints (including time, money, skills, etc.).
Every approach or technique mentioned above somewhat mitigates performance risks and improves chances that the system will perform up to expectations. However, none of them guarantees that. And, moreover, none completely replaces the others, as each one addresses different facets of performance.
A Closer Look at Load Testing
To illustrate that point of importance of each approach let’s look at load testing. With the recent trends towards agile development, DevOps, lean startups, and web operations, the importance of load testing gets sometimes questioned. Some (not many) are openly saying that they don’t need load testing while others are still paying lip service to it – but just never get there. In more traditional corporate world we still see performance testing groups and most important systems get load tested before deployment. So what load testing delivers that other performance engineering approaches don’t?
There are always risks of crashing a system or experiencing performance issues under heavy load – and the only way to mitigate them is to actually test the system. Even stellar performance in production and a highly scalable architecture don’t guarantee that it won’t crash under a slightly higher load.
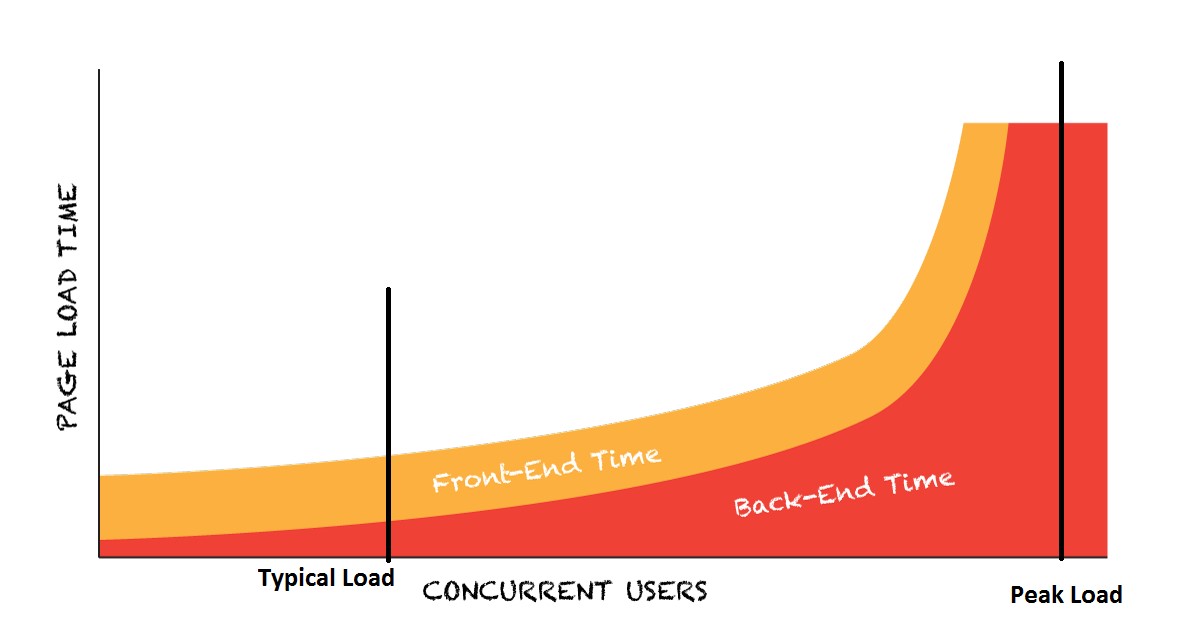 Fig.1. Typical response time curve.
Fig.1. Typical response time curve.
A typical response time curve is shown on fig.1, adapted from Andy Hawkes’ post When 80/20 Becomes 20/80 discussing the topic. As it can be seen, a relatively small increase in load near the curve knee may kill the system – so the system would be unresponsive (or crash) under the peak load.
Load testing doesn’t completely guarantee that the system won’t crash: for example, if the real-life workload would be different from what was tested (so you need to monitor the production system to verify that your synthetic load is close enough). But load testing significantly decreases the risk if done properly (and, of course, may be completely useless if done not properly – so it usually requires at least some experience and qualifications).
Another important value of load testing is checking how changes impact multi-user performance. The impact on multi-user performance is not usually proportional to what you see with single-user performance and often may be counterintuitive; sometimes single-user performance improvement may lead to multi-user performance degradation. And the more complex the system is, the more likely exotic multi-user performance issues may pop up.
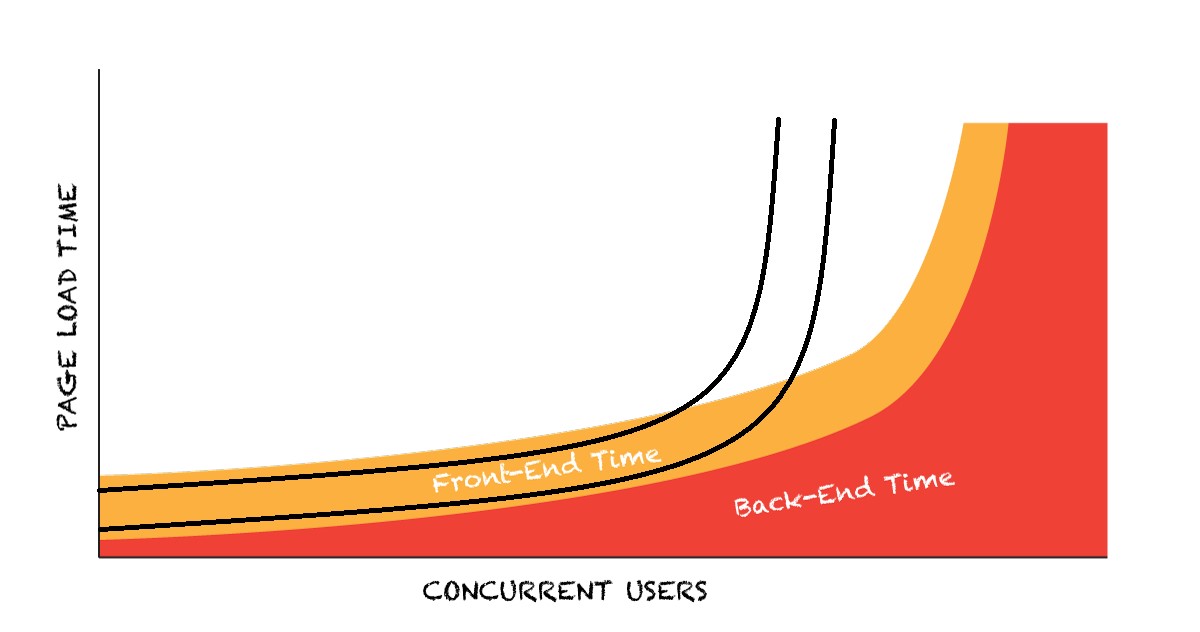 Fig.2 Single-user performance vs. multi-user performance.
Fig.2 Single-user performance vs. multi-user performance.
It can be seen on fig.2, where the black lines represent better single-user performance (lower on the left side of the graph), but worse multi-user load: the knee happens under a lower load and the system won’t able to reach the load it supported before.
Another major value of load testing is providing a reliable and reproducible way to apply multi-user load needed for performance optimization and performance troubleshooting. You apply exactly the same synthetic load and see if the change makes a difference. In most cases you can’t do it in production when load is changing – so you never know if the result comes from your code change or from change in the workload (except, maybe, a rather rare case of very homogeneous and very manageable workloads when you may apply a very precisely measured portion of the real workload). And, of course, a reproducible synthetic workload significantly simplifies debugging and verification of multi-user issues.
Moreover, with existing trends of system self-regulation (such as auto-scaling or changing the level of services depending on load), load testing is needed to verify that functionality. You need to apply heavy load to see how auto-scaling will work. So load testing becomes a way to test functionality of the system, blurring the traditional division between functional and nonfunctional testing.
Changing Dynamic
It may be possible to survive without load testing by using other ways to mitigate performance risks if the cost of performance issues and downtime is low. However, it actually means that you use customers to test your system, addressing only those issues that pop up; this approach become risky once performance and downtime start to matter.
The question is discussed in detail in Load Testing at Netflix: Virtual Interview with Coburn Watson. As explained there, Netflix was very successful in using canary testing in some cases instead of load testing. Actually canary testing is the performance testing that uses real users to create load instead of creating synthetic load by a load testing tool. It makes sense when 1) you have very homogenous workloads and can control them precisely 2) potential issues have minimal impact on user satisfaction and company image and you can easily rollback the changes 3) you have fully parallel and scalable architecture. That was the case with Netflix – they just traded in the need to generate (and validate) workload for a possibility of minor issues and minor load variability. But the further you are away from these conditions, the more questionable such practice would be.
Yes, the other ways to mitigate performance risks mentioned above definitely decrease performance risks comparing to situations where nothing is done about performance at all. And, perhaps, may be more efficient comparing with the old stereotypical way of doing load testing – running few tests at the last moment before rolling out the system in production without any instrumentation. But they still leave risks of crashing and performance degradation under multi-user load. So actually you need to have a combination of different performance engineering approaches to mitigate performance risks – but the exact mix depends on your system and your goals. Blindly copying approaches used, for example, by social networking companies onto financial or e-commerce systems may be disastrous.
As the industry is changing with all the modern trends, the components of performance engineering and their interactions is changing too. Still it doesn’t look like any particular one is going away. Some approaches and techniques need to be adjusted to new realities – but there is nothing new in that, we may see such changing dynamic throughout all the history of performance engineering.
Historical View
It is interesting to look how handling performance changed with time. Probably performance engineering went beyond single-user profiling when mainframes started to support multitasking, forming as a separate discipline in 1960-s. It was mainly batch loads with sophisticated ways to schedule and ration consumed resources as well as pretty powerful OS-level instrumentation allowing to track down performance issues. The cost of mainframe resources was high, so there were capacity planners and performance analysts to optimize mainframe usage.
Then the paradigm changed to client-server and distributed systems. Available operating systems didn’t have almost any instrumentation or workload management capabilities, so load testing became almost only remedy in addition to system-level monitoring to handle multi-user performance. Deploying across multiple machines was more difficult and the cost of rollback was significant, especially for Commercial Of-The-Shelf (COTS) software which may be deployed by thousands of customers. Load testing became probably the main way to ensure performance of distributed systems and performance testing groups became the centers of performance-related activities in many organizations.
While cloud looks quite different from mainframes, there are many similarities between them, especially from the performance point of view. Such as availability of computer resources to be allocated, an easy way to evaluate the cost associated with these resources and implement chargeback, isolation of systems inside a larger pool of resources, easier ways to deploy a system and pull it back if needed without impacting other systems.
However there are notable differences and they make managing performance in cloud more challenging. First of all, there is no instrumentation on the OS level and even resource monitoring becomes less reliable. So all instrumentation should be on the application level. Second, systems are not completely isolated from the performance point of view and they could impact each other (and even more so when we talk about containers). And, of course, we mostly have multi-user interactive workloads which are difficult to predict and manage. That means that such performance risk mitigation approaches as APM, load testing, and capacity management are very important in cloud.
So it doesn’t look like the need in particular performance risk mitigation approaches, such as load testing or capacity planning, is going away. Even in case of web operations, we would probably see load testing coming back as soon as systems become more complex and performance issues start to hurt business. Still the dynamic of using different approaches is changing (as it was during the whole history of performance engineering). Probably there would be less need for “performance testers” limited only to running tests – due to better instrumenting, APM tools, continuous integration, resource availability, etc. – but I’d expect more need for performance experts who would be able to see the whole picture using all available tools and techniques.
[The post was originally published in the November 2015 issue of Testing Circus – adapted to better fit the blog format]
